Solving the Problem of Inconsistent Responses to Basic Commands
Implementing Robust Error Handling and Feedback Mechanisms
Understanding the Importance of Error Handling
Robust error handling is crucial for any application, especially in scenarios where unexpected events can significantly impact user experience or data integrity. Implementing effective error handling mechanisms allows for graceful degradation in the face of problems, preventing application crashes and providing valuable feedback to users and developers. This proactive approach ensures that your application maintains stability and reliability, minimizing disruptions and enabling a positive user experience, even when things go wrong.
Without proper error handling, a seemingly minor issue can quickly escalate into a major problem. Applications might crash, data could be lost, and user trust could be eroded. By anticipating and addressing potential errors, you build a more resilient and trustworthy application.
Identifying Potential Errors and Their Types
A critical first step in implementing robust error handling is identifying the potential errors that might occur within your application. This involves careful consideration of the various inputs, processes, and external dependencies. Common error types include network failures, database connection problems, invalid user input, and resource limitations. Understanding the specific errors that your application might encounter is fundamental to creating targeted and effective error handling mechanisms.
Analyzing logs and user feedback is a key method to identify patterns in errors and their frequency. By understanding the context of errors, you can prioritize your efforts and focus on addressing the most prevalent and impactful issues.
Implementing Error Handling Strategies
Once potential errors are identified, strategies for handling them must be implemented. This often involves using try-catch blocks in programming languages to gracefully manage exceptions. These blocks allow your code to continue running even if an error occurs within a specific segment, preventing the entire application from crashing. Appropriate error codes and informative messages are also essential components of a robust error handling strategy, allowing users and developers to diagnose and resolve issues efficiently.
Implementing logging mechanisms to record error details, including timestamps, error messages, and relevant context, is another vital aspect of the strategy. This information can be invaluable for troubleshooting and identifying trends in errors over time.
Designing Effective Feedback Mechanisms
Error handling shouldn't just prevent crashes; it should also provide meaningful feedback to users. Clear and concise error messages, tailored to the user's role and technical understanding, are crucial. Avoid technical jargon and instead focus on providing actionable information. For example, instead of a cryptic error code, provide a message that explains the problem in user-friendly terms.
Providing alternative solutions or workarounds where possible can significantly improve the user experience during error conditions. This proactive approach demonstrates that you're committed to supporting the user, even when unexpected issues arise.
Monitoring and Evaluating Error Handling
Continuous monitoring and evaluation of your error handling mechanisms are crucial for ensuring their effectiveness. Regularly reviewing error logs, analyzing error frequencies, and tracking user feedback are important steps in this process. This data helps identify areas for improvement and allows you to refine your error handling strategies over time.
By actively monitoring and adapting your approach, you can optimize your error handling mechanisms to ensure the best possible user experience and maintain the stability and reliability of your application. This iterative approach allows for proactive adaptation to evolving needs and changing circumstances.
Optimizing Algorithm Performance and Efficiency
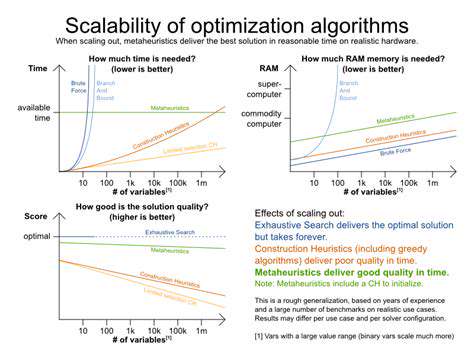
Algorithm Selection and Design
Choosing the right algorithm is crucial for optimizing performance. Consider the characteristics of your data and the specific task you're trying to achieve. Different algorithms excel in different scenarios. A brute-force approach might be acceptable for small datasets, but for large-scale problems, more sophisticated algorithms are essential to avoid excessive computation time. Understanding the time and space complexity of various algorithms is critical for making informed decisions.
The design of an algorithm significantly impacts its performance. Well-structured algorithms tend to be more efficient than poorly designed ones. Careful consideration of data structures and algorithmic steps can lead to substantial improvements in speed and resource utilization. For example, using a hash table instead of a linear search can drastically reduce the time complexity for lookups.
Data Structures for Efficiency
Appropriate data structures are fundamental to algorithm performance. Selecting the right data structure can significantly impact the efficiency of operations like searching, sorting, and insertion. For example, using a binary search tree for sorted data allows for logarithmic time complexity for search operations, which is much faster than linear search.
Choosing the correct data structure is essential for optimal performance. Consider the frequency and types of operations you'll need to perform on your data when making your choice. If you anticipate frequent insertions and deletions, a linked list might be a suitable option, whereas an array might be more appropriate for random access.
Time Complexity Analysis
Analyzing the time complexity of an algorithm is essential for understanding its performance characteristics. This involves determining how the execution time of the algorithm grows as the input size increases. Understanding Big O notation is key to this analysis, allowing you to compare the relative efficiency of different algorithms.
Time complexity analysis helps predict how an algorithm will perform under different input conditions. This allows you to identify bottlenecks and potential scalability issues before deployment, enabling proactive optimization efforts.
Space Complexity Considerations
Space complexity, or memory usage, is another critical aspect of algorithm performance. Efficient algorithms minimize the amount of memory required to execute, which is crucial for large datasets and resource-constrained environments. Understanding how memory usage grows with input size is essential for avoiding memory overflow errors and ensuring the algorithm functions effectively within available resources.
Input Data Characteristics and Preprocessing
The characteristics of the input data can significantly impact algorithm performance. Preprocessing steps, such as sorting or filtering the input data, can improve the efficiency of subsequent operations. For example, sorting a dataset before performing a binary search can drastically reduce the search time.
Data cleaning and preprocessing can significantly improve the efficiency of algorithms. Handling missing values or outliers can prevent unexpected behavior and improve accuracy. Careful consideration of input data characteristics and preprocessing techniques can lead to substantial performance gains.
Algorithm Implementation Techniques
Effective implementation techniques are crucial for achieving optimal performance. Utilizing appropriate programming paradigms, such as object-oriented programming, can improve code structure and readability, leading to more maintainable and efficient solutions. Careful coding practices, like avoiding unnecessary loops or recursive calls, can also reduce execution time.
Optimization Strategies and Techniques
Various optimization strategies and techniques can be employed to improve algorithm performance. Techniques like memoization and dynamic programming can significantly reduce redundant computations, leading to substantial speed improvements. Profiling tools can identify performance bottlenecks and guide optimization efforts.
Employing caching mechanisms can enhance performance by storing frequently accessed data or intermediate results. This can significantly reduce the time required to retrieve that data in subsequent calls, leading to faster processing. Careful application of such optimization techniques is essential for achieving the desired performance gains.
Read more about Solving the Problem of Inconsistent Responses to Basic Commands









Hot Recommendations
- The Impact of Early Socialization on a Dog's Interaction with Other Animals
- Car Travel and Puppy Socialization: Making the Journey a Positive Experience
- The Importance of Early Environmental Exposure for Puppy Development
- Taking Your Puppy to the Vet: Positive Socialization Strategies
- Making Training a Positive Experience for Your Puppy
- Public Transportation and Puppy Socialization: A Step by Step Guide
- Safe Socialization: Allowing Others to Pet Your Puppy
- Helping a Puppy Who Struggles with "Stay"
- Positive Puppy Interactions: Making Meetings with New Friends Fun
- No Treats Needed? Training Basic Commands with Verbal Praise